
این دوره جنبههای مهم اسکرپینگ وب سایتها با استفاده از Beautiful Soup را پوشش میدهد. شما یاد خواهید گرفت که درخت تجزیه را بسازید، دستکاری کنید و از آن عبور کنید، و همچنین از ویژگیهای پیشرفته مانند کار با فیلترها، CSS و XPath استفاده کنید.
آنچه خواهید آموخت: < br> Web scraping یک تکنیک مهم است که به طور گسترده به عنوان اولین گام در بسیاری از جریانهای کاری در داده کاوی، بازیابی اطلاعات و یادگیری ماشینی مبتنی بر متن استفاده میشود. در این دوره، استخراج دادهها از HTML با BeautifulSoup*، توانایی ساخت راهحلهای اسکرپینگ وب قوی و قابل نگهداری را با استفاده از کتابخانه Beautiful Soup در پایتون به دست خواهید آورد. ابتدا، یاد خواهید گرفت که چگونه میتوان از عبارات منظم برای حذف محتوای وب استفاده کرد و چگونه Beautiful Soup در راههای مهم بهتر عمل میکند. در مرحله بعد، خواهید دید که چگونه Beautiful Soup HTML را از محتوای وب تجزیه میکند، تگهای بد شکل را اصلاح میکند و یک درخت تجزیه تمیز و به راحتی قابل عبور میسازد. سپس خواهید دید که چگونه میتوان از درخت تجزیه برای یافتن و بازیابی الگوهای خاص استفاده کرد. در نهایت، با استفاده از ویژگیهای پیشرفته Beautiful Soup مانند کار با CSS و XPath، دانش خود را کامل میکنید. هنگامی که این دوره را به پایان رساندید، مهارت و دانش لازم برای پیادهسازی اسکراپینگ قوی وب با استفاده از Beautiful Soup را خواهید داشت.







نمونه ویدیوی آموزشی ( زیرنویسها جدا از ویدیو است و میتوانید آنرا نمایش ندهید ) :
[ENGLISH]
01 Course Overview [2mins]
01-01 Course Overview [2mins]
02 Getting Started with BeautifulSoup [44mins]
02-01 Version Check [0mins]
02-02 Module Overview [1mins]
02-03 Prerequisites and Course Outline [1mins]
02-04 Introducing Web Scraping [2mins]
02-05 Regular Expressions and Beautiful Soup [7mins]
02-06 Making GET Requests Using Httplib2, Urllib and Requests [8mins]
02-07 Introducing Regular Expressions [4mins]
02-08 Performing Simple Pattern Matches Using Regular Expressions [5mins]
02-09 Parsing Web Pages Using Regular Expressions [7mins]
02-10 Introducing Beautiful Soup [8mins]
02-11 Module Summary [1mins]
03 Navigating the Parse Tree [40mins]
03-01 Module Overview [1mins]
03-02 Parsing Web Pages with Beautiful Soup [5mins]
03-03 Tags, Attributes, NavigableStrings, Comments [4mins]
03-04 Navigating Using Tags and Contents [4mins]
03-05 Navigating Children, Descendants, and Parents [6mins]
03-06 Navigating Sideways Using Next and Previous Sibling [4mins]
03-07 Navigating Sideways Using Next Element and Previous Element [3mins]
03-08 Filter by Tags and Attributes Using Regular Expressions and Custom Functions [7mins]
03-09 Extracting Absolute and Relative Links from HTML [5mins]
03-10 Module Summary [1mins]
04 Searching for Elements in the Parse Tree [30mins]
04-01 Module Overview [1mins]
04-02 XML and XPath [4mins]
04-03 Performing Advanced Search on the Parse Tree [7mins]
04-04 Searching Using Variations of Find and Find All [4mins]
04-05 CSS Selectors Using Soup Sieve [7mins]
04-06 Using XPath to Navigate an XML Tree [5mins]
04-07 Module Summary [2mins]
05 Leveraging Advanced Features of BeautifulSoup [30mins]
05-01 Module Overview [1mins]
05-02 Modifying the HTML Parse Tree [6mins]
05-03 Exploring Beautiful Soup Functions to Modify the Parse Tree [6mins]
05-04 Miscellaneous Operations Using Beautiful Soup [6mins]
05-05 Working with Different Parsers [4mins]
05-06 Using the Soup Strainer to Parse Parts of a Document [2mins]
05-07 Encodings in Beautiful Soup [3mins]
05-08 Summary and Further Study [2mins]
[فارسی]
01 بررسی اجمالی دوره [2 دقیقه]
01-01 بررسی اجمالی دوره [2 دقیقه]
02 شروع با BeautifulSoup [44 دقیقه]
02-01 بررسی نسخه [0 دقیقه]
02-02 نمای کلی ماژول [1 دقیقه]
02-03 پیش نیازها و خلاصه دوره [1 دقیقه]
02-04 معرفی Web Scraping [2 دقیقه]
02-05 عبارات منظم و سوپ زیبا [7 دقیقه]
02-06 ایجاد درخواست GET با استفاده از Httplib2، Urllib و Requests [8 دقیقه]
02-07 معرفی عبارات منظم [4 دقیقه]
02-08 انجام تطابق الگوهای ساده با استفاده از عبارات منظم [5 دقیقه]
02-09 تجزیه صفحات وب با استفاده از عبارات منظم [7 دقیقه]
02-10 معرفی سوپ زیبا [8 دقیقه]
02-11 خلاصه ماژول [1 دقیقه]
03 پیمایش درخت پارس [40 دقیقه]
03-01 نمای کلی ماژول [1 دقیقه]
03-02 تجزیه صفحات وب با سوپ زیبا [5 دقیقه]
03-03 برچسبها، ویژگیها، رشتههای قابل هدایت، نظرات [4 دقیقه]
03-04 پیمایش با استفاده از برچسبها و مطالب [4 دقیقه]
03-05 پیمایش کودکان، فرزندان و والدین [6 دقیقه]
03-06 پیمایش به طرفین با استفاده از خواهر یا برادر بعدی و قبلی [4 دقیقه]
03-07 پیمایش به طرفین با استفاده از عنصر بعدی و عنصر قبلی [3 دقیقه]
03-08 فیلتر بر اساس برچسبها و ویژگیها با استفاده از عبارات منظم و توابع سفارشی [7 دقیقه]
03-09 استخراج پیوندهای مطلق و نسبی از HTML [5 دقیقه]
03-10 خلاصه ماژول [1 دقیقه]
04 جستجوی عناصر در درخت تجزیه [30 دقیقه]
04-01 نمای کلی ماژول [1 دقیقه]
04-02 XML و XPath [4 دقیقه]
04-03 انجام جستجوی پیشرفته در درخت تجزیه [7 دقیقه]
04-04 جستجو با استفاده از تغییرات Find and Find All [4 دقیقه]
04-05 انتخابگرهای CSS با استفاده از غربال سوپ [7 دقیقه]
04-06 استفاده از XPath برای پیمایش درخت XML [5 دقیقه]
04-07 خلاصه ماژول [2 دقیقه]
05 استفاده از ویژگیهای پیشرفته BeautifulSoup [30 دقیقه]
05-01 نمای کلی ماژول [1 دقیقه]
05-02 اصلاح درخت تجزیه HTML [6 دقیقه]
05-03 کاوش در عملکردهای زیبای سوپ برای اصلاح درخت پارس [6 دقیقه]
05-04 عملیات متفرقه با استفاده از سوپ زیبا [6 دقیقه]
05-05 کار با تجزیه کنندههای مختلف [4 دقیقه]
05-06 استفاده از صافی سوپ برای تجزیه بخشی از یک سند [2 دقیقه]
05-07 رمزگذاری در سوپ زیبا [3 دقیقه]
05-08 خلاصه و مطالعه بیشتر [2 دقیقه]
جانانی راوی


Janani Ravi
جانانی راوی
جانانی دارای مدرک کارشناسی ارشد از استنفورد است و بیش از 7 سال در گوگل کار کرده است. او یکی از مهندسان اصلی Google Docs بود و دارای 4 پتنت برای فریمورک ویرایش مشارکتی بلادرنگ آن است. جانانی پس از گذراندن سالها کار در فناوری در منطقه خلیج، نیویورک و سنگاپور در شرکتهایی مانند مایکروسافت، گوگل و فلیپکارت، سرانجام تصمیم گرفت عشق خود به فناوری را با علاقهاش به تدریس ترکیب کند. او اکنون یکی از بنیانگذاران Loonycorn است، یک استودیوی محتوا که بر ارائه محتوای با کیفیت بالا برای توسعه مهارتهای فنی متمرکز است. Loonycorn در حال کار بر روی توسعه یک موتور (پتنت ثبت شده) برای خودکارسازی انیمیشنها برای ارائهها و محتوای آموزشی است.





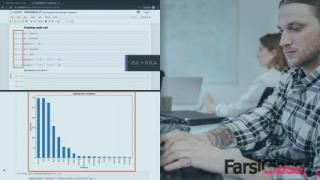
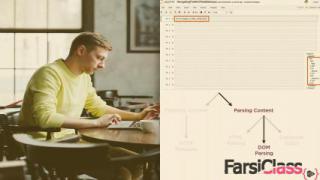
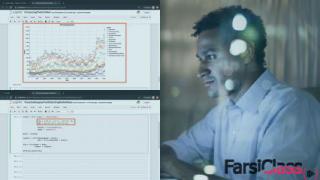




















فارسی کلاس (FarsiClass.ir) سایتی منحصر بفرد در ایران، شامل آموزش های IT تخصصی و حرفه ای سایت پلورال سایت (Pluralsight) با زیرنویس فارسی و انگلیسی.
+ ما آموزش های یکی از تخصصی ترین سایتهای سازنده آموزشهای ویدیویی در جهان، یعنی پلورال سایت (Pluralsight) را فارسی سازی کرده و در اختیار شما قرار دادهایم.
+ زیرنویسهای فارسی آموزشها، با جدیدترین تکنولوژی هوش مصنوعی (Artificial Intelligence به اختصار AI)، ترجمه شده و پس از آن، طی چند مرحله بصورت هوشمند، مورد بازبینی و ویرایش قرار میگیرد.
+ تمامی آموزشهای سایت فارسی کلاس، با زیرنویس فارسی و انگلیسی و با کیفیت ویدیوئی عالی (1280x720) ارائه میگردد.
