
این دوره به شما میآموزد که چگونه میتوانید مدلهای یادگیری ماشین سنتی خود را با استفاده از زمان اجرا Databricks Machine Learning و MLflow بسازید و آموزش دهید تا چرخه عمر یادگیری ماشینی را مدیریت کنید.
آنچه یاد خواهید گرفت:
آموزش، ارزیابی و استقرار مدلهای یادگیری ماشین در حال حاضر در بسیاری از سازمانها امری عادی است، و داشتن این فرآیند اغلب بخشی از محیط مناسب شرکت است. Databricks Machine Learning Runtime، همراه با MLFlow، اجرای آزمایش شما را مدیریت میکند و مدلها آموزش و تنظیم فراپارامتر مدلهای شما را ساده و شهودی میکنند. در این دوره آموزشی، ساخت مدلهای یادگیری ماشین روی Databricks، ساخت و آموزش مدلهای رگرسیون و طبقهبندی با استفاده از فریمورک scikit-learn را خواهید آموخت. ابتدا، دادههای خود را با استفاده از نوتبوکهای Databricks بارگیری، کاوش و پردازش میکنید و از Bamboolib برای تجزیه و تحلیل و تبدیل دادههای بدون کد استفاده میکنید. در مرحله بعد، آزمایشهایی ایجاد میکنید و پارامترها و معیارهای مدل خود را با استفاده از اجراها دنبال میکنید و اجراها را با استفاده از رابط کاربری MLflow مقایسه میکنید. پس از آن، مدلهای رگرسیون و طبقهبندی را با استفاده از الگوریتمهای تقویت گرادیان که بخشی از فریمورک XGBoost هستند، میسازید و آموزش میدهید. شما همچنین مدلهای خود را با استفاده از سرویس مدل کلاسیک MLFlow تولید و ارائه خواهید کرد و با استفاده از مدلهای مستقر شده خود استنتاج بلادرنگ انجام میدهید. در نهایت، یاد خواهید گرفت که چگونه میتوانید از ابزار Hyperopt برای تنظیم هایپرپارامتر مدلهای خود و همچنین اجرای تنظیم هایپرپارامتر به صورت توزیع شده بر روی یک کلاستر Spark با استفاده از کلاس SparkTrials استفاده کنید. پس از اتمام این دوره، مهارتها و دانش لازم برای ساخت و آموزش مدلهای یادگیری ماشین سنتی بر روی Databricks را با استفاده از MLflow برای مدیریت گردش کار یادگیری ماشین خود خواهید داشت.







نمونه ویدیوی آموزشی ( زیرنویسها جدا از ویدیو است و میتوانید آنرا نمایش ندهید ) :
[ENGLISH]
01 Course Overview [2mins]
01-01 Course Overview [2mins]
02 Introducing Machine Learning on Databricks [24mins]
02-01 Prequisites and Course Outline [2mins]
02-02 Overview of Databricks [5mins]
02-03 The Databricks Machine Learning Runtime [4mins]
02-04 Introducing MLflow [7mins]
02-05 Demo: Getting Set up with the Machine Learning Environment on Databricks [6mins]
03 Implementing scikit-learn Models in Databricks [50mins]
03-01 A Quick Overview of scikit-learn [3mins]
03-02 Demo: Loading, Exploring, and Preprocessing Data [4mins]
03-03 Demo: Creating an Experiment and Run [4mins]
03-04 Demo: Autologging to Track Model Metrics [8mins]
03-05 Demo: Creating Multiple Runs and Comparing Runs [5mins]
03-06 Demo: Using Loaded Model for Predictions [3mins]
03-07 Demo: Using Bamboolib for Data Exploration and Transformation [6mins]
03-08 Demo: Autologging to Track Metrics for a Classification Model [5mins]
03-09 Demo: Registering Models and Managing Stage Transitions [5mins]
03-10 Demo: Classic Inferencing Using a REST Endpoint [7mins]
04 Implementing XGBoost Models in Databricks [38mins]
04-01 An Overview of XGBoost [5mins]
04-02 Demo: Inferring Model Signature and Logging Models [6mins]
04-03 Demo: Autologging XGBoost Model Runs [6mins]
04-04 Machine Learning Using Apache Spark [3mins]
04-05 Demo: Loading Data into a Delta Table [3mins]
04-06 Demo: Training a Model Using a Spark ML Pipeline [8mins]
04-07 Demo: Training an XGBoost Model Using a Spark Pipeline [2mins]
04-08 Demo: Using Cross Validation to Find the Best Model Hyperparameters [5mins]
05 Hyperparameter Tuning for Machine Learning Models [28mins]
05-01 Understanding Hyperparameter Tuning [3mins]
05-02 Hyperopt for Hyperparameter Tuning [5mins]
05-03 Demo: Explicitly Logging Model Parameters [5mins]
05-04 Demo: Hyperparameter Tuning Using Hyperopt [8mins]
05-05 Demo: Hyperparameter Training Using Different Classifiers [6mins]
05-06 Summary and Further Study [1mins]
[فارسی]
01 بررسی اجمالی دوره [2 دقیقه]
01-01 بررسی اجمالی دوره [2 دقیقه]
02 معرفی یادگیری ماشینی روی Databricks [24 دقیقه]
02-01 پیش نیازها و خلاصه دوره [2 دقیقه]
02-02 نمای کلی Databricks [5 دقیقه]
02-03 زمان اجرای یادگیری ماشین Databricks [4 دقیقه]
02-04 معرفی MLflow [7 دقیقه]
02-05 نسخهی نمایشی- راه اندازی با محیط یادگیری ماشین روی Databricks [6 دقیقه]
03 پیادهسازی مدلهای یادگیری scikit در Databricks [50 دقیقه]
03-01 مروری سریع بر آموزش اسکیکت [3 دقیقه]
03-02 نسخهی نمایشی- بارگیری، کاوش، و پیش پردازش دادهها [4 دقیقه]
03-03 نسخهی نمایشی- ایجاد یک آزمایش و اجرا [4 دقیقه]
03-04 نسخهی نمایشی- ثبت خودکار برای ردیابی معیارهای مدل [8 دقیقه]
03-05 نسخهی نمایشی- ایجاد چندین اجرا و مقایسه اجراها [5 دقیقه]
03-06 نسخهی نمایشی- استفاده از مدل بارگذاری شده برای پیش بینی [3 دقیقه]
03-07 نسخهی نمایشی- استفاده از Bamboolib برای کاوش و تبدیل داده [6 دقیقه]
03-08 نسخهی نمایشی- ثبت خودکار برای ردیابی معیارها برای یک مدل طبقهبندی [5 دقیقه]
03-09 نسخهی نمایشی- ثبت مدلها و مدیریت انتقال مرحله [5 دقیقه]
03-10 نسخهی نمایشی- استنتاج کلاسیک با استفاده از نقطه پایانی REST [7 دقیقه]
04 پیادهسازی مدلهای XGBoost در Databricks [38 دقیقه]
04-01 مروری بر XGBoost [5 دقیقه]
04-02 نسخهی نمایشی- استنباط مدلهای امضا و گزارش گیری مدل [6 دقیقه]
04-03 نسخهی نمایشی- اجرای خودکار XGBoost مدل [6 دقیقه]
04-04 یادگیری ماشین با استفاده از اسپارک آپاچی [3 دقیقه]
04-05 نسخهی نمایشی- بارگیری دادهها در یک جدول دلتا [3 دقیقه]
04-06 نسخهی نمایشی- آموزش یک مدل با استفاده از Spark ML Pipeline [8 دقیقه]
04-07 نسخهی نمایشی- آموزش مدل XGBoost با استفاده از Spark Pipeline [2 دقیقه]
04-08 نسخهی نمایشی- استفاده از Cross Validation برای یافتن بهترین هایپرپارامترهای مدل [5 دقیقه]
05 تنظیم فراپارامتر برای مدلهای یادگیری ماشین [28 دقیقه]
05-01 آشنایی با تنظیم فراپارامتر [3 دقیقه]
05-02 Hyperopt برای تنظیم Hyperparameter [5 دقیقه]
05-03 نسخه آزمایشی- ثبت صریح پارامترهای مدل [5 دقیقه]
05-04 نسخهی نمایشی- تنظیم Hyperparameter با استفاده از Hyperopt [8 دقیقه]
05-05 نسخهی نمایشی- آموزش Hyperparameter با استفاده از طبقهبندی کنندههای مختلف [6 دقیقه]
05-06 خلاصه و مطالعه بیشتر [1 دقیقه]
جانانی راوی


Janani Ravi
جانانی راوی
جانانی دارای مدرک کارشناسی ارشد از استنفورد است و بیش از 7 سال در گوگل کار کرده است. او یکی از مهندسان اصلی Google Docs بود و دارای 4 پتنت برای فریمورک ویرایش مشارکتی بلادرنگ آن است. جانانی پس از گذراندن سالها کار در فناوری در منطقه خلیج، نیویورک و سنگاپور در شرکتهایی مانند مایکروسافت، گوگل و فلیپکارت، سرانجام تصمیم گرفت عشق خود به فناوری را با علاقهاش به تدریس ترکیب کند. او اکنون یکی از بنیانگذاران Loonycorn است، یک استودیوی محتوا که بر ارائه محتوای با کیفیت بالا برای توسعه مهارتهای فنی متمرکز است. Loonycorn در حال کار بر روی توسعه یک موتور (پتنت ثبت شده) برای خودکارسازی انیمیشنها برای ارائهها و محتوای آموزشی است.





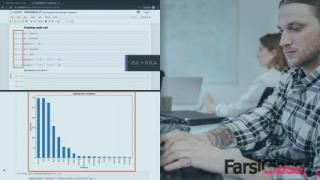
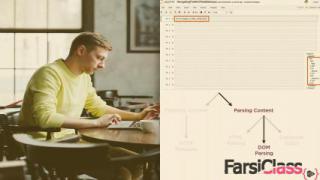
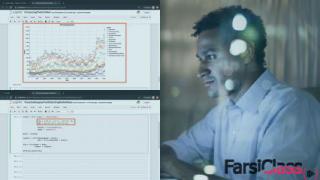


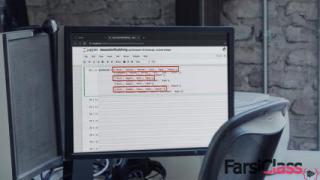







فارسی کلاس (FarsiClass.ir) سایتی منحصر بفرد در ایران، شامل آموزش های IT تخصصی و حرفه ای سایت پلورال سایت (Pluralsight) با زیرنویس فارسی و انگلیسی.
+ ما آموزش های یکی از تخصصی ترین سایتهای سازنده آموزشهای ویدیویی در جهان، یعنی پلورال سایت (Pluralsight) را فارسی سازی کرده و در اختیار شما قرار دادهایم.
+ زیرنویسهای فارسی آموزشها، با جدیدترین تکنولوژی هوش مصنوعی (Artificial Intelligence به اختصار AI)، ترجمه شده و پس از آن، طی چند مرحله بصورت هوشمند، مورد بازبینی و ویرایش قرار میگیرد.
+ تمامی آموزشهای سایت فارسی کلاس، با زیرنویس فارسی و انگلیسی و با کیفیت ویدیوئی عالی (1280x720) ارائه میگردد.
