
این دوره جنبههای استخراج اطلاعات از اسناد متنی و ساخت مدلهای طبقهبندی از جمله بردارسازی ویژگی، درهمسازی حساس به محل، حذف کلید واژه، واژهسازی و موارد دیگر را از پردازش زبان طبیعی پوشش میدهد.
آنچه خواهید آموخت:
از رباتهای گفتگو تا ادبیات تولید شده توسط ماشین، برخی از داغترین کاربردهای ML و AI این روزها برای دادهها به شکل متنی هستند.







نمونه ویدیوی آموزشی ( زیرنویسها جدا از ویدیو است و میتوانید آنرا نمایش ندهید ) :
[ENGLISH]
01 Course Overview [2mins]
01-01 Course Overview [2mins]
02 Representing Text as Features for Machine Learning [35mins]
02-01 Version Check [0mins]
02-02 Module Overview [1mins]
02-03 Prerequisites and Course Outline [1mins]
02-04 One-hot Encoding [4mins]
02-05 Count Vectors [3mins]
02-06 Tf-Idf Vectors [3mins]
02-07 Co-occurence Vectors [5mins]
02-08 Word Embeddings [5mins]
02-09 Installing Packages and Setting Up the Environment [3mins]
02-10 Sentence and Word Tokenization [5mins]
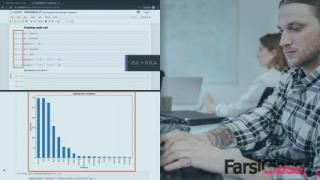
02-11 Plotting Word Frequency Distributions [4mins]
02-12 Module Summary [1mins]
03 Building Feature Vector Representations of Text [27mins]
03-01 Module Overview [1mins]
03-02 Bag-of-words and Bag-of-n-grams [3mins]
03-03 Bag-of-words Using the Count Vectorizer [7mins]
03-04 Inverse Transform Using the Count Vectorizer [2mins]
03-05 Bag-of-n-grams Using the Count Vectorizer [6mins]
03-06 Generating N-grams Using NLTK [3mins]
03-07 Bag-of-words Using the Tf-Idf Vectorizer [4mins]
03-08 Module Summary [1mins]
04 Simplifying Text Processing Using Natural Language Processing [34mins]
04-01 Module Overview [1mins]
04-02 Natural Language Processing Operations [6mins]
04-03 Stopword Removal Using NLTK and scikit-learn [7mins]
04-04 Frequency Filtering Using scikit-learn [3mins]
04-05 Stemming [6mins]
04-06 Lemmatization [4mins]
04-07 Parts-of-speech Tagging [6mins]
04-08 Module Summary [1mins]
05 Reducing Dimensions in Text Using Hashing [26mins]
05-01 Module Overview [1mins]
05-02 Feature Hashing [2mins]
05-03 Reducing Dimensions Using the Feature Hasher [4mins]
05-04 Reducing Dimensions at Scale Using the Hashing Vectorizer [6mins]
05-05 Locality-sensitive Hashing [5mins]
05-06 Similar Documents Using Jaccard Index and Locality-sensitive Hashing [7mins]
05-07 Module Summary [1mins]
06 Applying Text Feature Extraction Techniques to Machine Learning [28mins]
06-01 Module Overview [1mins]
06-02 Naive Bayes for Classification [3mins]
06-03 Classification Using the Hashing Vectorizer [8mins]
06-04 Pre-process Text Using a Stemmer, Build Features Using the Hashing Vectorizer [3mins]
06-05 Building Features Using the Count Vectorizer [2mins]
06-06 Pre-processing with Stopword Removal, Building Features Using Count Vectorizer [2mins]
06-07 Pre-processing with Stopword Removal, Frequency Filtering, Building Features Using Count Vectorizer [3mins]
06-08 Building Features Using the Tf-Idf Vectorizer [2mins]
06-09 Building Features Using Bag-of-n-grams Model [2mins]
06-10 Summary and Further Study [2mins]
[فارسی]
01 بررسی اجمالی دوره [2 دقیقه]
01-01 بررسی اجمالی دوره [2 دقیقه]
02 نمایش متن به عنوان ویژگی برای یادگیری ماشین [35 دقیقه]
02-01 بررسی نسخه [0 دقیقه]
02-02 نمای کلی ماژول [1 دقیقه]
02-03 پیش نیازها و خلاصه دوره [1 دقیقه]
02-04 رمزگذاری یکباره [4 دقیقه]
02-05 شمارش بردارها [3 دقیقه]
02-06 وکتورهای Tf-Idf [3 دقیقه]
02-07 بردارهای همزمان [5 دقیقه]
02-08 جاسازی کلمه [5 دقیقه]
02-09 نصب بستهها و تنظیم محیط [3 دقیقه]
02-10 رمزگذاری جمله و کلمه [5 دقیقه]
02-11 ترسیم توزیع فرکانس کلمه [4 دقیقه]
02-12 خلاصه ماژول [1 دقیقه]
03 ساختن نمایش بردار ویژگی متن [27 دقیقه]
03-01 نمای کلی ماژول [1 دقیقه]
03-02 کیسهای از کلمات و کیسهای از n گرم [3 دقیقه]
03-03 مجموعه کلمات با استفاده از شمارش بردار [7 دقیقه]
03-04 تبدیل معکوس با استفاده از بردار شمارش [2 دقیقه]
03-05 کیسهای از n گرم با استفاده از بردار شمارش [6 دقیقه]
03-06 تولید N-گرم با استفاده از NLTK [3 دقیقه]
03-07 مجموعه کلمات با استفاده از بردار Tf-Idf [4 دقیقه]
03-08 خلاصه ماژول [1 دقیقه]
04 ساده کردن پردازش متن با استفاده از پردازش زبان طبیعی [34 دقیقه]
04-01 نمای کلی ماژول [1 دقیقه]
04-02 عملیات پردازش زبان طبیعی [6 دقیقه]
04-03 حذف کلمات کلیدی با استفاده از NLTK و یادگیری اسکیت [7 دقیقه]
04-04 فیلتر فرکانس با استفاده از scikit-learn [3 دقیقه]
04-05 ساقه زدن [6 دقیقه]
04-06 Lemmatization [4 دقیقه]
04-07 برچسبگذاری بخشهای گفتار [6 دقیقه]
04-08 خلاصه ماژول [1 دقیقه]
05 کاهش ابعاد در متن با استفاده از هش کردن [26 دقیقه]
05-01 نمای کلی ماژول [1 دقیقه]
05-02 درهم کردن ویژگی [2 دقیقه]
05-03 کاهش ابعاد با استفاده از هاشر ویژگی [4 دقیقه]
05-04 کاهش ابعاد در مقیاس با استفاده از Hashing Vectorizer [6 دقیقه]
05-05 هش کردن حساس به محلی [5 دقیقه]
05-06 اسناد مشابه با استفاده از Jaccard Index و هش کردن حساس به محل [7 دقیقه]
05-07 خلاصه ماژول [1 دقیقه]
06 استفاده از تکنیکهای استخراج ویژگی متن در یادگیری ماشینی [28 دقیقه]
06-01 نمای کلی ماژول [1 دقیقه]
06-02 بیز ساده برای طبقهبندی [3 دقیقه]
06-03 طبقهبندی با استفاده از Hashing Vectorizer [8 دقیقه]
06-04 پیش پردازش متن با استفاده از Stemmer، ساخت ویژگیها با استفاده از Hashing Vectorizer [3 دقیقه]
06-05 ویژگیهای ساختمان با استفاده از شمارش بردار [2 دقیقه]
06-06 پیش پردازش با حذف Stopword، ایجاد ویژگیهای با استفاده از Count Vectorizer [2 دقیقه]
06-07 پیش پردازش با حذف Stopword، فیلتر فرکانس، ویژگیهای ساختمان با استفاده از Count Vectorizer [3 دقیقه]
06-08 ویژگیهای ساختمان با استفاده از وکتوریزر Tf-Idf [2 دقیقه]
06-09 ویژگیهای ساختمان با استفاده از مدل کیسهای از n گرم [2 دقیقه]
06-10 خلاصه و مطالعه بیشتر [2 دقیقه]
جانانی راوی


Janani Ravi
جانانی راوی
جانانی دارای مدرک کارشناسی ارشد از استنفورد است و بیش از 7 سال در گوگل کار کرده است. او یکی از مهندسان اصلی Google Docs بود و دارای 4 پتنت برای فریمورک ویرایش مشارکتی بلادرنگ آن است. جانانی پس از گذراندن سالها کار در فناوری در منطقه خلیج، نیویورک و سنگاپور در شرکتهایی مانند مایکروسافت، گوگل و فلیپکارت، سرانجام تصمیم گرفت عشق خود به فناوری را با علاقهاش به تدریس ترکیب کند. او اکنون یکی از بنیانگذاران Loonycorn است، یک استودیوی محتوا که بر ارائه محتوای با کیفیت بالا برای توسعه مهارتهای فنی متمرکز است. Loonycorn در حال کار بر روی توسعه یک موتور (پتنت ثبت شده) برای خودکارسازی انیمیشنها برای ارائهها و محتوای آموزشی است.














فارسی کلاس (FarsiClass.ir) سایتی منحصر بفرد در ایران، شامل آموزش های IT تخصصی و حرفه ای سایت پلورال سایت (Pluralsight) با زیرنویس فارسی و انگلیسی.
+ ما آموزش های یکی از تخصصی ترین سایتهای سازنده آموزشهای ویدیویی در جهان، یعنی پلورال سایت (Pluralsight) را فارسی سازی کرده و در اختیار شما قرار دادهایم.
+ زیرنویسهای فارسی آموزشها، با جدیدترین تکنولوژی هوش مصنوعی (Artificial Intelligence به اختصار AI)، ترجمه شده و پس از آن، طی چند مرحله بصورت هوشمند، مورد بازبینی و ویرایش قرار میگیرد.
+ تمامی آموزشهای سایت فارسی کلاس، با زیرنویس فارسی و انگلیسی و با کیفیت ویدیوئی عالی (1280x720) ارائه میگردد.
