
این دوره ابزارهای مهم برای بازیابی محتوای وب با استفاده از کتابخانههای HTTP مانند Requests، Httplib2 و Urllib و همچنین فناوریهای قدرتمند برای تجزیه وب را پوشش میدهد. اینها عبارتند از Beautiful Soup، که یک کتابخانه محبوب است، و Scrapy، که یک فریمورک قدرتمند و درجه تولید است.
آنچه خواهید آموخت:
اسکرپینگ وب یک ابزار تکنیک مهمی که به طور گسترده به عنوان اولین گام در بسیاری از گردشهای کاری در داده کاوی، بازیابی اطلاعات و یادگیری ماشینی مبتنی بر متن استفاده میشود. در این دوره، خراش دادن اولین صفحه وب خود با پایتون، توانایی اعمال تکنیکهای مختلف خراش دادن از جمله سوپ زیبا و اسکرپی را به دست خواهید آورد. ابتدا، کتابخانههای مختلف سرویس گیرنده HTTP مانند Requests، httplib2 و urllib را برای دانلود محتوای HTML یاد میگیرید و از آنها استفاده میکنید. در مرحله بعد، متوجه خواهید شد که چگونه Beautiful Soup یک کتابخانه بسیار محبوب پایتون است که به روشهای مهمی بهتر از regex عمل میکند. خواهید دید که چگونه Beautiful Soup HTML بد شکل گرفته را اصلاح میکند و یک درخت تجزیه زیبا میسازد که میتوان آن را پیمایش کرد و پرس و جو کرد. در نهایت، دانش Scrapy را به جعبه ابزار خود اضافه میکنید، که یک فریمورک تمام عیار اسکراپی وب است که مراحل بازیابی و تجزیه محتوای وب را ترکیب میکند و این کار را در مقیاس تولید انجام میدهد. وقتی این دوره را به پایان رساندید، مهارتها و دانش لازم برای شناسایی نقاط قوت و موارد استفاده فناوریهای مختلف بازیابی وب و خراش دادن مانند عبارات منظم، سوپ زیبا و اسکرپی را خواهید داشت.







نمونه ویدیوی آموزشی ( زیرنویسها جدا از ویدیو است و میتوانید آنرا نمایش ندهید ) :
[ENGLISH]
01 Course Overview [2mins]
01-01 Course Overview [2mins]
02 Getting Started with Web Scraping [45mins]
02-01 Version Check [0mins]
02-02 Module Overview [1mins]
02-03 Prerequisites and Course Outline [1mins]
02-04 HTTP Requests and Responses [6mins]
02-05 Web Scraping [2mins]
02-06 HTTP Client Libraries [4mins]
02-07 Making GET Requests Using httplib2 [7mins]
02-08 Making OPTIONS, POST, PUT Requests with httplib2 [4mins]
02-09 Handling Redirects with httplib2 [4mins]
02-10 Making HTTP Requests and Parsing URLs Using urllib [7mins]
02-11 GET and POST Requests Using the Requests Library [5mins]
02-12 Handling Redirects with the Requests Library [3mins]
02-13 Module Summary [1mins]
03 Working with the Parse Tree in BeautifulSoup [39mins]
03-01 Module Overview [1mins]
03-02 The HTML Parse Tree [4mins]
03-03 Beautiful Soup for HTML Parsing [2mins]
03-04 Introducing Beautiful Soup [5mins]
03-05 Extracting Specific Page Elements [6mins]
03-06 Filtering Elements Using Find and Find All [7mins]
03-07 Searching and Filtering Using Custom Functions [3mins]
03-08 Extracting Links from a Page [6mins]
03-09 Using a Soup Strainer to Parse a Subset of a Document [4mins]
03-10 Module Summary [1mins]
04 Selecting Elements Using the Scrapy Shell [35mins]
04-01 Module Overview [1mins]
04-02 Parsing Web Content [2mins]
04-03 Introducing Scrapy [4mins]
04-04 Getting Started with Scrapy [4mins]
04-05 Introducing the Scrapy Shell [4mins]
04-06 Selecting Elements Using CSS Selectors [7mins]
04-07 Advanced Selections Using CSS Selectors [5mins]
04-08 Selecting Elements Using XPath Selectors [7mins]
04-09 Module Summary [1mins]
05 Scraping Web Sites Using Scrapy Spiders [34mins]
05-01 Module Overview [1mins]
05-02 How Scrapy Works [3mins]
05-03 Creating Your First Custom Spider [7mins]
05-04 Writing Scraped Contents to a File [2mins]
05-05 Exploring Items Using the Scrapy Shell [4mins]
05-06 Using Items to Store Extracted Content [4mins]
05-07 Using Item Loaders and Input and Output Processors for Scraped Data [7mins]
05-08 Using Pipelines to Transform Scraped Data [5mins]
05-09 Module Summary [1mins]
[فارسی]
01 بررسی اجمالی دوره [2 دقیقه]
01-01 بررسی اجمالی دوره [2 دقیقه]
02 شروع کار با Web Scraping [45 دقیقه]
02-01 بررسی نسخه [0 دقیقه]
02-02 نمای کلی ماژول [1 دقیقه]
02-03 پیش نیازها و خلاصه دوره [1 دقیقه]
02-04 درخواستها و پاسخهای HTTP [6 دقیقه]
02-05 خراش دادن وب [2 دقیقه]
02-06 کتابخانههای سرویس گیرنده HTTP [4 دقیقه]
02-07 ایجاد درخواست GET با استفاده از httplib2 [7 دقیقه]
02-08 ایجاد OPTIONS، POST، PUT درخواست با httplib2 [4 دقیقه]
02-09 مدیریت تغییر مسیرها با httplib2 [4 دقیقه]
02-10 ایجاد درخواستهای HTTP و تجزیه URLها با استفاده از urllib [7 دقیقه]
02-11 دریافت و ارسال درخواستها با استفاده از کتابخانه درخواستها [5 دقیقه]
02-12 مدیریت تغییر مسیرها با کتابخانه درخواستها [3 دقیقه]
02-13 خلاصه ماژول [1 دقیقه]
03 کار با درخت پارس در BeautifulSoup [39 دقیقه]
03-01 نمای کلی ماژول [1 دقیقه]
03-02 درخت تجزیه HTML [4 دقیقه]
03-03 سوپ زیبا برای تجزیه HTML [2 دقیقه]
03-04 معرفی سوپ زیبا [5 دقیقه]
03-05 استخراج عناصر خاص صفحه [6 دقیقه]
03-06 فیلتر کردن عناصر با استفاده از Find and Find All [7 دقیقه]
03-07 جستجو و فیلتر کردن با استفاده از توابع سفارشی [3 دقیقه]
03-08 استخراج پیوندها از یک صفحه [6 دقیقه]
03-09 استفاده از صافی سوپ برای تجزیه زیر مجموعهای از یک سند [4 دقیقه]
03-10 خلاصه ماژول [1 دقیقه]
04 انتخاب عناصر با استفاده از پوسته Scrapy [35 دقیقه]
04-01 نمای کلی ماژول [1 دقیقه]
04-02 تجزیه محتوای وب [2 دقیقه]
04-03 معرفی اسکرپی [4 دقیقه]
04-04 شروع کار با Scrapy [4 دقیقه]
04-05 معرفی پوسته Scrapy [4 دقیقه]
04-06 انتخاب عناصر با استفاده از انتخابگرهای CSS [7 دقیقه]
04-07 انتخابهای پیشرفته با استفاده از انتخابگرهای CSS [5 دقیقه]
04-08 انتخاب عناصر با استفاده از انتخابگرهای XPath [7 دقیقه]
04-09 خلاصه ماژول [1 دقیقه]
05 خراش دادن وب سایتها با استفاده از Scrapy Spiders [34 دقیقه]
05-01 نمای کلی ماژول [1 دقیقه]
05-02 Scrapy چگونه کار میکند [3 دقیقه]
05-03 ایجاد اولین عنکبوت سفارشی شما [7 دقیقه]
05-04 نوشتن مطالب خراشیده شده در یک فایل [2 دقیقه]
05-05 کاوش موارد با استفاده از پوسته Scrapy [4 دقیقه]
05-06 استفاده از موارد برای ذخیره محتوای استخراج شده [4 دقیقه]
05-07 استفاده از لودرهای آیتم و پردازشگرهای ورودی و خروجی برای دادههای خراشیده شده [7 دقیقه]
05-08 استفاده از Pipelines برای تبدیل دادههای خراشیده شده [5 دقیقه]
05-09 خلاصه ماژول [1 دقیقه]
جانانی راوی


Janani Ravi
جانانی راوی
جانانی دارای مدرک کارشناسی ارشد از استنفورد است و بیش از 7 سال در گوگل کار کرده است. او یکی از مهندسان اصلی Google Docs بود و دارای 4 پتنت برای فریمورک ویرایش مشارکتی بلادرنگ آن است. جانانی پس از گذراندن سالها کار در فناوری در منطقه خلیج، نیویورک و سنگاپور در شرکتهایی مانند مایکروسافت، گوگل و فلیپکارت، سرانجام تصمیم گرفت عشق خود به فناوری را با علاقهاش به تدریس ترکیب کند. او اکنون یکی از بنیانگذاران Loonycorn است، یک استودیوی محتوا که بر ارائه محتوای با کیفیت بالا برای توسعه مهارتهای فنی متمرکز است. Loonycorn در حال کار بر روی توسعه یک موتور (پتنت ثبت شده) برای خودکارسازی انیمیشنها برای ارائهها و محتوای آموزشی است.





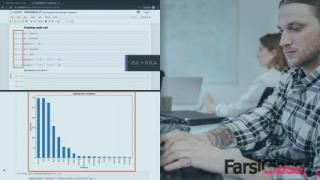
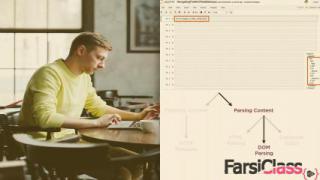
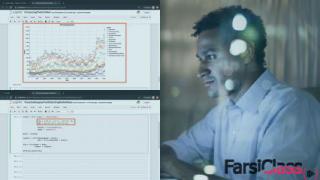


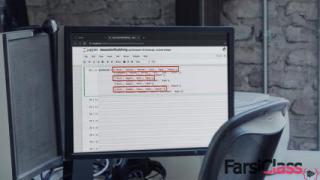









فارسی کلاس (FarsiClass.ir) سایتی منحصر بفرد در ایران، شامل آموزش های IT تخصصی و حرفه ای سایت پلورال سایت (Pluralsight) با زیرنویس فارسی و انگلیسی.
+ ما آموزش های یکی از تخصصی ترین سایتهای سازنده آموزشهای ویدیویی در جهان، یعنی پلورال سایت (Pluralsight) را فارسی سازی کرده و در اختیار شما قرار دادهایم.
+ زیرنویسهای فارسی آموزشها، با جدیدترین تکنولوژی هوش مصنوعی (Artificial Intelligence به اختصار AI)، ترجمه شده و پس از آن، طی چند مرحله بصورت هوشمند، مورد بازبینی و ویرایش قرار میگیرد.
+ تمامی آموزشهای سایت فارسی کلاس، با زیرنویس فارسی و انگلیسی و با کیفیت ویدیوئی عالی (1280x720) ارائه میگردد.
