
این دوره تکنیکهای مهم در ارزیابی مدل برای برخی از محبوبترین انواع تکنیکهای داده کاوی را پوشش میدهد. این تکنیکها از یادگیری قوانین تداعی گرفته تا خوشهبندی، رگرسیون و طبقهبندی را شامل میشود.
آنچه خواهید آموخت:
دادهکاوی اصطلاحی است که برای تکنیکهایی استفاده میشود که الگوها را در مجموعه دادههای بزرگ بنابراین، داده کاوی را میتوان به طور موثر به عنوان استفاده از تکنیکهای یادگیری ماشین برای دادههای بزرگ در نظر گرفت. در این دوره، ارزیابی یک مدل داده کاوی، توانایی پاسخگویی به دو سوال مهم را که هر دست اندرکار داده کاوی باید به آنها پاسخ دهد - آیا مدل خاصی برای این دادهها معتبر است؟ و اگر بله، آن مدل به ما چه میگوید؟ ابتدا، خواهید آموخت که ارزیابی تناسب مدل و تفسیر نتایج مدل، مراحل کلیدی در فرآیند داده کاوی هستند. در مرحله بعد، متوجه خواهید شد که چگونه یادگیری قواعد مرتبط - یک تکنیک کلاسیک داده کاوی - پیادهسازی و ارزیابی میشود. در نهایت، دانش خود را با مشاهده اینکه چگونه تکنیکهای راهحل رایج ML - رگرسیون، طبقهبندی، و خوشهبندی - میتوانند پیادهسازی و برای تناسب ارزیابی شوند، کامل میکنید. پس از اتمام این دوره، مهارتها و دانش لازم برای پیادهسازی تکنیکهای داده کاوی، ارزیابی آنها از نظر تناسب مدل و سپس تفسیر هوشمندانه یافتههای آنها را خواهید داشت.







نمونه ویدیوی آموزشی ( زیرنویسها جدا از ویدیو است و میتوانید آنرا نمایش ندهید ) :
[ENGLISH]
01 Course Overview [2mins]
01-01 Course Overview [2mins]
02 Evaluating the Effectiveness of a Clustering Model [48mins]
02-01 Version Check [0mins]
02-02 Module Overview [2mins]
02-03 Prerequisites and Course Outline [1mins]
02-04 Evaluating the Results of Data Mining [6mins]
02-05 White-box Models and Concept Drift [4mins]
02-06 Model Simplicity [5mins]
02-07 Evaluating Clustering Models [7mins]
02-08 Demo: Performing Clustering Analysis Using K-means Clustering [7mins]
02-09 Demo: Performing Clustering Analysis Using Agglomerative Clustering and Mean Shift Clustering [4mins]
02-10 Demo: Evaluating K-means Clustering Using Sum of Squared Distances and Silhoutte Score [5mins]
02-11 Demo: Evaluating Agglomerative Clustering and Estimating the Right Bandwidth for Mean Shift Clustering [5mins]
02-12 Module Summary [2mins]
03 Evaluating the Effectiveness of Association Rule Mining [40mins]
03-01 Module Overview [2mins]
03-02 Association Rule Mining for Market Basket Analysis [3mins]
03-03 Support and Frequent Itemsets [4mins]
03-04 Confidence, Lift, and Conviction [8mins]
03-05 An Overview of the Apriori Algorithm [3mins]
03-06 Demo: Using the Apriori Algorithm to Generate Frequent Itemsets [7mins]
03-07 Demo: Association Rule Mining on a Toy Dataset [5mins]
03-08 Demo: Exploring the Bread Basket Dataset [4mins]
03-09 Demo: Association Rule Mining Using the Bread Basket Data [3mins]
03-10 Module Summary [1mins]
04 Evaluating the Effectiveness of Regression Models [36mins]
04-01 Module Overview [1mins]
04-02 Finding the Best Fit Line [3mins]
04-03 Interpreting Regression Results [3mins]
04-04 R-square and Adjusted R-square [3mins]
04-05 T-statistics and F-statistic [2mins]
04-06 Demo: Exploring the Regression Dataset [6mins]
04-07 Demo: Building and Evaluating a Regression Model [5mins]
04-08 Demo: Interpreting Results Using Residuals and Learning Curves [5mins]
04-09 Demo: Evaluating Multiple Regression Models [7mins]
04-10 Module Summary [1mins]
05 Evaluating the Effectiveness of Classification Models [42mins]
05-01 Module Overview [1mins]
05-02 Accuracy as an Evaluation Metric [2mins]
05-03 Precision and Recall to Evaluate Classifiers [5mins]
05-04 The ROC Curve [5mins]
05-05 Validating Models Using Training, Validation, and Test Sets [5mins]
05-06 K-fold Cross Validation [3mins]
05-07 Demo: Exploring the Classification Dataset [5mins]
05-08 Demo: K-fold, Hold-out, and Shuffle Split Cross Validation [6mins]
05-09 Demo: Grid Search for Hyperparameter Tuning with Cross Validation [5mins]
05-10 Demo: Evaluating the Model Using Accuracy, Precision, Recall and the ROC Curve [3mins]
05-11 Module Summary [2mins]
[فارسی]
01 بررسی اجمالی دوره [2 دقیقه]
01-01 بررسی اجمالی دوره [2 دقیقه]
02 ارزیابی اثربخشی یک مدل خوشهبندی [48 دقیقه]
02-01 بررسی نسخه [0 دقیقه]
02-02 نمای کلی ماژول [2 دقیقه]
02-03 پیش نیازها و خلاصه دوره [1 دقیقه]
02-04 ارزیابی نتایج داده کاوی [6 دقیقه]
02-05 مدلهای جعبه سفید و دریفت مفهومی [4 دقیقه]
02-06 مدل سادگی [5 دقیقه]
02-07 ارزیابی مدلهای خوشهبندی [7 دقیقه]
02-08 نسخهی نمایشی- انجام تجزیه و تحلیل خوشهبندی با استفاده از خوشهبندی K-means [7 دقیقه]
02-09 نسخه آزمایشی- انجام تجزیه و تحلیل خوشهبندی با استفاده از خوشهبندی تجمعی و خوشهبندی میانگین شیفت [4 دقیقه]
02-10 نسخهی نمایشی- ارزیابی خوشهبندی K-means با استفاده از مجموع فاصلههای مربعی و امتیاز تصویر [5 دقیقه]
02-11 نسخهی نمایشی- ارزیابی خوشهبندی تجمعی و تخمین پهنای باند مناسب برای خوشهبندی میانگین شیفت [5 دقیقه]
02-12 خلاصه ماژول [2 دقیقه]
03 ارزیابی اثربخشی کاوی قانون انجمن [40 دقیقه]
03-01 نمای کلی ماژول [2 دقیقه]
03-02 استخراج قانون انجمن برای تحلیل سبد بازار [3 دقیقه]
03-03 پشتیبانی و مجموعه آیتمهای مکرر [4 دقیقه]
03-04 اعتماد به نفس، بالابردن، و اعتقاد [8 دقیقه]
03-05 مروری بر الگوریتم Apriori [3 دقیقه]
03-06 نسخهی نمایشی- استفاده از الگوریتم Apriori برای ایجاد مجموعههای مکرر [7 دقیقه]
03-07 نسخهی نمایشی- استخراج قوانین انجمن در مجموعه داده اسباب بازی [5 دقیقه]
03-08 نسخهی نمایشی- کاوش مجموعه داده سبد نان [4 دقیقه]
03-09 نسخهی نمایشی- استخراج قوانین انجمن با استفاده از دادههای سبد نان [3 دقیقه]
03-10 خلاصه ماژول [1 دقیقه]
04 ارزیابی اثربخشی مدلهای رگرسیون [36 دقیقه]
04-01 نمای کلی ماژول [1 دقیقه]
04-02 یافتن بهترین خط مناسب [3 دقیقه]
04-03 تفسیر نتایج رگرسیون [3 دقیقه]
04-04 R-square و R-square تنظیم شده [3 دقیقه]
04-05 آمار T و آمار F [2 دقیقه]
04-06 نسخهی نمایشی- کاوش مجموعه دادههای رگرسیون [6 دقیقه]
04-07 نسخهی نمایشی- ساخت و ارزیابی یک مدل رگرسیون [5 دقیقه]
04-08 نسخهی نمایشی- تفسیر نتایج با استفاده از پسماندها و منحنیهای یادگیری [5 دقیقه]
04-09 نسخهی نمایشی- ارزیابی مدلهای رگرسیون چندگانه [7 دقیقه]
04-10 خلاصه ماژول [1 دقیقه]
05 ارزیابی اثربخشی مدلهای طبقهبندی [42 دقیقه]
05-01 نمای کلی ماژول [1 دقیقه]
05-02 دقت به عنوان معیار ارزیابی [2 دقیقه]
05-03 دقت و یادآوری برای ارزیابی طبقهبندیکنندهها [5 دقیقه]
05-04 منحنی ROC [5 دقیقه]
05-05 اعتبارسنجی مدلها با استفاده از مجموعههای آموزشی، اعتبارسنجی و تست [5 دقیقه]
05-06 K-fold Cross Validation [3 دقیقه]
05-07 نسخهی نمایشی- کاوش مجموعه دادههای طبقهبندی [5 دقیقه]
05-08 نسخه نمایشی- K-fold، Hold-out و Shuffle Split Cross Validation [6 دقیقه]
05-09 نسخهی نمایشی- جستجوی شبکه برای تنظیم فراپارامتر با اعتبارسنجی متقاطع [5 دقیقه]
05-10 نسخهی نمایشی- ارزیابی مدل با استفاده از دقت، دقت، یادآوری و منحنی ROC [3 دقیقه]
05-11 خلاصه ماژول [2 دقیقه]
جانانی راوی


Janani Ravi
جانانی راوی
جانانی دارای مدرک کارشناسی ارشد از استنفورد است و بیش از 7 سال در گوگل کار کرده است. او یکی از مهندسان اصلی Google Docs بود و دارای 4 پتنت برای فریمورک ویرایش مشارکتی بلادرنگ آن است. جانانی پس از گذراندن سالها کار در فناوری در منطقه خلیج، نیویورک و سنگاپور در شرکتهایی مانند مایکروسافت، گوگل و فلیپکارت، سرانجام تصمیم گرفت عشق خود به فناوری را با علاقهاش به تدریس ترکیب کند. او اکنون یکی از بنیانگذاران Loonycorn است، یک استودیوی محتوا که بر ارائه محتوای با کیفیت بالا برای توسعه مهارتهای فنی متمرکز است. Loonycorn در حال کار بر روی توسعه یک موتور (پتنت ثبت شده) برای خودکارسازی انیمیشنها برای ارائهها و محتوای آموزشی است.





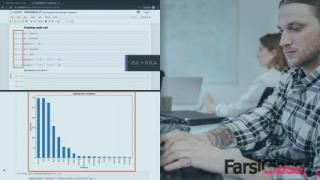
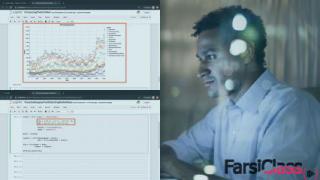











فارسی کلاس (FarsiClass.ir) سایتی منحصر بفرد در ایران، شامل آموزش های IT تخصصی و حرفه ای سایت پلورال سایت (Pluralsight) با زیرنویس فارسی و انگلیسی.
+ ما آموزش های یکی از تخصصی ترین سایتهای سازنده آموزشهای ویدیویی در جهان، یعنی پلورال سایت (Pluralsight) را فارسی سازی کرده و در اختیار شما قرار دادهایم.
+ زیرنویسهای فارسی آموزشها، با جدیدترین تکنولوژی هوش مصنوعی (Artificial Intelligence به اختصار AI)، ترجمه شده و پس از آن، طی چند مرحله بصورت هوشمند، مورد بازبینی و ویرایش قرار میگیرد.
+ تمامی آموزشهای سایت فارسی کلاس، با زیرنویس فارسی و انگلیسی و با کیفیت ویدیوئی عالی (1280x720) ارائه میگردد.
